Однозначно ніхто не може сказати, чи здатна дана схема з існуючим числом кореневих DNS серверів протистояти розподіленим DoS атак в разі використання бот мереж з мільйонами хостів.
ICCAN оголосив, що з 2009 року можна буде зареєструвати домени верхнього рівня, а це означає, що навантаження на кореневі DNS сервера додатково зросте. Кореневі DNS сервера Інтернет періодично атакують, використовуючи бот мережі. Бот мережі розростаються до величезних розмірів. Практично жодна з комерційних організацій не способу протистояти DoS атакам з використанням бот-мереж.
Давайте розберемося, що «хороші хлопці», відповідальні за працездатність кореневих DNS серверів протиставляють «поганим хлопцям», які, можливо, будуть атакувати ці сервера.
Не секрет, що функціонування всього Інтернет дуже сильно зав'язане на систему DNS. Коли ви відкриваєте сторінку вашим Інтернет оглядачем, ваш поштовий сервер починає передавати лист, ваш SIP IP телефон викликає іншого абонента, і в тисячах інших випадків, задіюється процес визначення місця розташування того чи іншого сервісу за допомогою DNS. Якщо з яких - небудь причин DNS перестане працювати, це спричинить за собою неминучі простої. Не будемо розбиратися в мотивації тих, хто намагається вивести з ладу глобальну систему DNS, залишимо це дядечкові Фрейду. Краще з'ясуємо, чому атаці піддаються саме кореневі DNS і що це взагалі таке.
Щоб розібратися, чому атакують саме кореневі сервери DNS необхідно розуміти, як працює ця система. Графічно, структуру DNS коректніше представити у вигляді дерева.
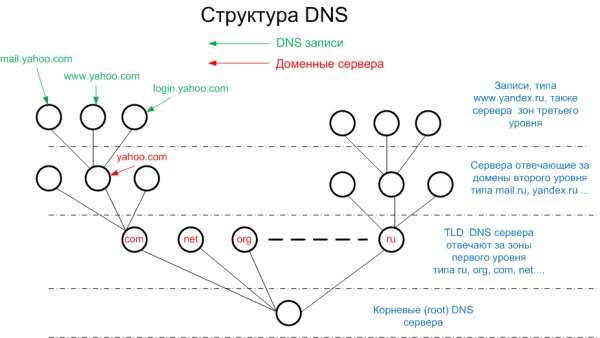
У корені дерева розташовані так звані кореневі сервери. Їх всього 13 штук. Кореневі сервери знають про місце положення (IP адреси) так званих TLD (Top Level Domain) серверів. TLD сервера обслуговують великі зони першого рівня, такі як com, net, ru, kz, ua, gov .... Група TLD серверів знає про місце положення серверів обслуговуючих домени другого рівня в межах їх зони відповідальності. Наприклад, відповідальні за домен com знають IP адреси серверів другого рівня для зони першого рівня com, відповідальні за зону ru знають про серверах зони ru, ну і так далі. Сервера відповідальні за зони другого рівня вже, як правило, знають конкретні адреси серверів, що надають послуги інтернету, таких як www, mail і т.д. Також сервера другого рівня можуть бути відповідальними за домени третього рівня, ну і так далі.
Для того, щоб зрозуміти як вся структура функціонує, розглянемо як це працює на прикладі визначення IP адреси сервера www.securityab.ru. Для спрощення, розглянемо приклад роботи рекурсивного DNS без урахування механізмів кешування.
Все, що спочатку відомо сервера, який надає послуги DNS це 13 IP адрес кореневих серверів. У моїй улюбленій ОС FreeBSD вони жорстко прописані у файлі named.root, у вашій улюбленій ОС, вони, можливо, зберігаються в інших місцях, але, ці IP адреси однозначно одна з найбільш постійних речей Інтернету.
Припустимо, клієнт запитує IP адреса сервера www.securitylab.ru сервер DNS, який його обслуговує. Той, в свою чергу, запитує про це кореневі сервери, при цьому IP адреса кореневого сервера вибирається довільно. Один з кореневих серверів йому відповідає, що нічого не знає про www.securitylab.ru, але, запитати про це можна у одного з 6-ти (на даний момент) TLD серверів, відповідальних за зону ru. Сервер DNS запитує один з серверів TLD, який відповідає, що треба б запитати про це один з трьох серверів відповідальних за зону другого рівня securitylab.ru. Сервер DNS дає третій запит до одного з серверів другого рівня, і, нарешті, дізнається що www.securitylab.ru живе на IP адресу 217.16.31.134.
Все це справедливо, якщо ви не використовуєте при роботі з DNS кешування (запам'ятовуєте результати попередніх запитів). Кешування на увазі, що після першого запиту сервер вже знає адреси серверів, які зберігають інформацію про зону ru і securitylab.ru і, власне, де розташований www.securitylab.ru.
Кешування вигідно всім. Менше запитів до кореневих і TLD серверів, менше трафіку витрачає сервер DNS провайдера, менше часу клієнт чекає відповіді від DNS сервера провайдера.
З глобальної точки зору, найсильніший позитивний ефект від кешування отримують саме кореневі сервери. І ще, завдяки кешування, найсильніша навантаження в DNS доводиться, що не на кореневі сервери, бо вони надають інформацію тільки про серверах TLD, а на TLD сервера, так як вони змушені давати відповіді на запити нема про сотнях, як кореневі півночі, а про мільйонах доменів. TLD півночі зазвичай могутніше кореневих, як з точки зору пропускної здатності мережі, що забезпечує їх функціонування, так і з точки зору обчислювальних ресурсів цих серверів.
Технічно, простіше завалити TLD сервера. Однак, не дивлячись на це, атакують найчастіше, саме кореневі сервери, так як, зрубів гілка, навіть дуже велику, таку як com, net або org ,, ви всього лише, зрубаєте частина дерева, але не весь DNS. Убивши ж корінь, ви досягнете максимального ефекту.
Виходячи зі знань про кешуванні, можна зробити ще один цікавий висновок. Якщо одноразово відключити всі кореневі сервери, то Інтернет помре аж ніяк не відразу. Однак проблеми у багатьох кінцевих користувачів почнуться практично відразу. На поточний момент все кореневі DNS сервера в цілому обробляють, десятки, а то і сотні тисяч запитів в секунду.
Взагалі, проблема при розподілених DoS атаках на кореневі DNS сервера зовсім не в тому, що вони не встигають обробляти запити. Основна проблема в тому, що вони стають недоступними через мережу. Фактично, щоб викликати відмову в обслуговуванні всієї системи DNS, атакуючим досить одночасно вивести з ладу 13 географічно розподілених точок мережі. Звичайно, можна прописати ще кілька десятків серверів в якості кореневих. Однак це складно з точки зору того, що необхідно буде міняти налаштування програмного забезпечення на всіх клієнтах. Крім того, така система не гарантує раціонального розподілу трафіку між кореневими серверами.
Як інший рішення протистояння розподіленим DoS атак на поточний момент впроваджена вкрай масштабируемая система з використанням anycast. Розглянемо, що це таке.
Не дивлячись на те, що технологія anycast була описана ще в листопаді 1993 року в RFC 1546, дуже мало мережевих професіоналів знають, що це таке. Справа тут не в складності технології, а скоріше в тому, що її використання обмежене вузькою областю застосування.
Слово anycast утворюється від двох англійських слів any - будь-який, cast - кидати, або, в термінах мережі, віщати. Взагалі в мережі розрізняють 4 методу мовлення - broadcast, multicast, unicast і anycast.
Якщо ви відкриєте Вікіпедію по cast-ам то побачите там 4 красивих малюнка ілюструють їх. Дозволю собі їх використовувати.
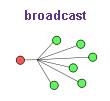 broadcast-и передаються від віщає одночасно всім. За аналогією з реальним світом у віщає є мегафон, за допомогою якого він розмовляє з натовпом людей. Його чують все, але радіус дії мегафона обмежений. Прикладом використання broadcast-а є процес видачі IP адреси хосту по протоколу DHCP. У мережах broadcast-и зазвичай не поширюються далі локальної мережі.
broadcast-и передаються від віщає одночасно всім. За аналогією з реальним світом у віщає є мегафон, за допомогою якого він розмовляє з натовпом людей. Його чують все, але радіус дії мегафона обмежений. Прикладом використання broadcast-а є процес видачі IP адреси хосту по протоколу DHCP. У мережах broadcast-и зазвичай не поширюються далі локальної мережі.
 multicast більше схожий на радіо. Радіус дії у нього може бути великий, проте ви його не почуєте, поки не включите радіо, в термінах мережі не підпишеться на послугу. Приклад використання multicast-а - IPTV, коли ви перемикаєте канали на своїй IPTV приставці, ви підписуєтеся на певний канал multicast мовлення, і тільки після цього вам доставляється картинка зі звуком. При цьому на один і той же канал можуть підписатися одночасно багато користувачів.
multicast більше схожий на радіо. Радіус дії у нього може бути великий, проте ви його не почуєте, поки не включите радіо, в термінах мережі не підпишеться на послугу. Приклад використання multicast-а - IPTV, коли ви перемикаєте канали на своїй IPTV приставці, ви підписуєтеся на певний канал multicast мовлення, і тільки після цього вам доставляється картинка зі звуком. При цьому на один і той же канал можуть підписатися одночасно багато користувачів.
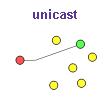 unicast можна порівняти з телефоном. Набравши певний номер, ви розмовляєте з певною людиною. У мережі, вказавши IP адреса, протокол і порт, ви спілкуєтеся з певним сервером. Більшість спілкувань між хостами в Інтернет відбувається за технологією unicast. Прикладів використання unicast десятків безліч - від закачування файлів по ftp до передачі електронної пошти.
unicast можна порівняти з телефоном. Набравши певний номер, ви розмовляєте з певною людиною. У мережі, вказавши IP адреса, протокол і порт, ви спілкуєтеся з певним сервером. Більшість спілкувань між хостами в Інтернет відбувається за технологією unicast. Прикладів використання unicast десятків безліч - від закачування файлів по ftp до передачі електронної пошти.
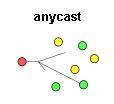 anycast найбільше схожий на unicast, його можна порівняти зі звичайним телефонним розмовою, за тим винятком, що ви додзвонюєтеся нема на конкретну людину, а на довідкову службу. Всі оператори довідкової служби рівноцінні і вам зовсім не важливо з ким з них ви говорите. Завдання телефонної станції в цьому випадку, при додзвоні користувачів на один і той же номер - вибір довільного оператора. Завдання мережі в разі роботи з anycast-му - вибір, за деякими критеріями, одного з рівноцінних серверів, з яким буде спілкуватися хост. З точки зору двох хостів, що беруть участь в anycast спілкуванні немає ніякої різниці в роботі в порівнянні з unicast-му.
anycast найбільше схожий на unicast, його можна порівняти зі звичайним телефонним розмовою, за тим винятком, що ви додзвонюєтеся нема на конкретну людину, а на довідкову службу. Всі оператори довідкової служби рівноцінні і вам зовсім не важливо з ким з них ви говорите. Завдання телефонної станції в цьому випадку, при додзвоні користувачів на один і той же номер - вибір довільного оператора. Завдання мережі в разі роботи з anycast-му - вибір, за деякими критеріями, одного з рівноцінних серверів, з яким буде спілкуватися хост. З точки зору двох хостів, що беруть участь в anycast спілкуванні немає ніякої різниці в роботі в порівнянні з unicast-му.
Щоб зрозуміти, як працює anycast необхідно мати уявлення про те, як працює маршрутизація в мережах використовують протокол IP.
Якщо два хоста, що беруть участь в обміні даними один з одним перебувають в різних подсетях, то пакети між ними доставляються за допомогою виконують спеціальні функції пристроїв мережі, які називаються маршрутизаторами.
Часто, два віддалених хоста в Інтернеті пов'язані між собою надлишковими зв'язками. Часом, пакет даних відісланий від хоста A теоретично може досягти хоста Б десятками різних шляхів. Зовсім не факт, що якщо пакет від хоста А пройшов через 3 певних маршрутизатора, то зворотний пакет від хоста Б прийде через ті ж 3 маршрутизатора. Наявність надлишкових зв'язків дає 2 основні переваги, перше - вихід з ладу одного з каналів зв'язку не означатиме недоступності для групи хостів, друге - навантаження при передачі даних може розподілятися між різними каналами, в результаті загальна пропускна здатність мережі зростає.
У процесі прийняття рішення, через який з можливих шляхів переслати пакет маршрутизатор керується, перш за все, адресою призначення пакета і логікою маршрутизації. Зазвичай, маршрутизатор не керівництво інформацією про джерело (хто послав пакет), протоколі, портах та іншою інформацією заголовків пакету даних. Але, наприклад, у маршрутизаторів cisco є особлива фіча, так званий PBR (Policy-Based Routing) http://www.cisco.com/en/US/docs/ios/12_2/qos/configuration/guide/qcfclass.html#wpxref35843
, Однак, це швидше виняток, ніж правило.
Забавно, але навіть мережевики зі стажем не завжди чітко уявляють, що служить критерієм прийняття рішення про направлення пакетів з того чи іншого маршруту. Найпростіша задача, на зображенні нижче вводить їх в ступор.
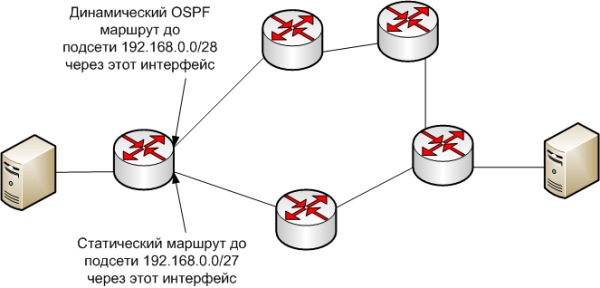
Питання: пакет на хост 192.168.0.2 піде з верхнього або нижнього інтерфейсу?
Правильна відповідь - з верхнього. Чому? Тому, що при виборі кращого маршруту послідовно спрацьовують наступні 3 правила.
1) Якщо довжини префіксів підмереж, в які потрапляє IP адреса хоста призначення різні, то вибирається маршрут з найдовшим префіксом.
2) Якщо префікси рівні, то вибирається маршрут з більш пріоритетним протоколом маршрутизації.
3) Якщо і префікси рівні і протоколи однакові, то спрацьовує внутрішній метрика протоколу маршрутизації.
В даному прикладі спрацювало перше правило.
А тепер трохи детальніше. Що таке префікс? Префікс це метод опису підмережі. Префікс складається з двох частин, ліва - ідентифікатор підмережі, права - довжина цього ідентифікатора.
Найдовший префікс має довжину 32 при цьому ліва частина такого префікса, по суті, є IP адресою. Найкоротший префікс має довжину 0, при цьому ліва частина префікса також дорівнює 0, такий префікс записується як 0/0 або 0.0.0.0/0, і в нього потрапляють всі можливі IP адреси.
В маршрутизації для опису підмереж використовуються префікси, але не ідентифікатори підмереж і маски. Запис 192.168.0.0/28 описує підмережа, в префікс якої послідовно 28 одиниць (довжина префікса), що еквівалентно записи 192.168.0.0 маска 255.255.255.240. Взагалі, тут кілька тонке питання відмінності, але маски використовуються для того, щоб обчислити чи стосується хост до певної підмережі, префікси служать для опису значущою для маршрутизації інформації про місцезнаходження підмереж. Є ще деякі неістотні, в даному контексті відмінності.
Маршрути можуть вноситися ручками в конфігурацію маршрутизатора, це називається статична маршрутизація, а можуть з'являтися там автоматично, за допомогою протоколів динамічної маршрутизації.
Основний принцип динамічної маршрутизації простий. Кожен маршрутизатор знає про кількох мережах доступних через нього. Після включення динамічної маршрутизації сусідні маршрутизатори починають обмінюватися інформацією про доступні через них мережах. Зрештою, після повного обміну маршрутної інформацією у кожного маршрутизатора з'являється повне уявлення про всі подсетях в межах автономної системи маршрутизації (наприклад, які є підмережі, через які інтерфейси вони доступні, як далеко вони розташовані). У разі, якщо відбуваються деякі події, наприклад пропадає лінк між маршрутизаторами, або вносяться / видаляються певні підмережі, таблиці маршрутизації автоматично перераховуються.
Кілька слів про пріоритети протоколів маршрутизації. Статична маршрутизація має найвищий пріоритет, різні протоколи динамічної маршрутизації мають кожен свій пріоритет. У прикладі, наведеному вище, якби префікси підмереж збігалися, то пакет, згідно з другим правилом, був би переданий через нижній інтерфейс. Область дії пріоритетів протоколів маршрутизації локальна для кожного маршрутизатора. Якщо маршрутизатор A отримав маршрут для мережі 192.168.0.0/28 через статичний маршрут, а маршрутизатор B отримав маршрут 192.168.0.0/28 від маршрутизаторів A і C по OSPF, то маршрутизатор B у виборі пріоритетів керується метриками OSPF. Тобто маршрутизатора не важливо, як сусіди дізналися про той чи інший маршрут, важливо тільки те, як і що він про нього дізнався.
Тепер варто пояснити, що таке метрики протоколів маршрутизації. Метрики це деякі внутрішні атрибути протоколу маршрутизації, на підставі яких приймаються рішення направити пакет по тому, або іншим шляхом. Якщо ви використовуєте статичну маршрутизацію, то природно, метрики ви виставляєте вручну, коли прописуєте маршрут. У випадку з динамічної маршрутизацією метрики, як і маршрут, найчастіше обчислюються автоматично, проте, їх також можна міняти і руками, змушуючи маршрутизатор кидати пакети по потрібному шляху.
Різні протоколи динамічної маршрутизації вираховують метрики різними способами. Для прикладу поверхнево розглянемо критерії вибору маршруту протоколом динамічної маршрутизації OSPF.
OSPF - Open Shortest Path first, вільно це можна перевести як кращий (маршрут) - з найменшим доступним шляхом. Це означає, що в разі рівнозначних (за швидкістю) зв'язків між вузлами мережі вибирається маршрут з найменшою кількістю маршрутизаторів через які він буде слідувати. На довжину шляху автоматично впливає швидкість, з якою працює інтерфейс. Наприклад, якщо інтерфейс працює на швидкості 100 Мбіт / c, то шлях до сусіда буде дорівнює 1, якщо 10Мбіт / c, то він буде дорівнює 10 і т.д. Вплинути на дистанцію можна і ручками. Для цього треба просто прописати на потрібному інтерфейсі параметр bandwith (ємність), який не впливає на фізичну швидкість інтерфейсу, але впливає на процес прийняття рішення маршрутизації.
На закінчення, хотілося б пояснити, чому правила маршрутизації спрацьовують саме в такому, але не в іншому порядку. Насправді, все дуже просто і логічно.
Правило номер 1.
Задумайтесь, як описати, де розташовані виходи з вашої мережі, в якій крутиться, припустимо, той же OSPF. Природно, на маршрутизаторах, де вони (виходи) розташовані треба прописати маршрут за замовчуванням (default gateway). У маршрут за замовчуванням повинні включатися всі можливі IP адреси. Як описується default gateway в префіксах? Ось так - 0/0. Будь-IP адреса потрапляє в префікс 0/0, однак пакети на default gateway повинні кидатися тільки в тому випадку, якщо інші маршрути не спрацьовують (адреса призначення не потрапляє ні в один інший існуючий префікс маршрутизації). Default gateway - той же маршрут, він так само передається між маршрутизаторами протоколом OSPF, отже, маршрути з більш довгим префіксом завжди робляться більш пріоритетними, для того, щоб схема з маршрутом за замовчуванням працювала.
Правило номер 2.
Метрики різних протоколів маршрутизації не співмірні. Набагато простіше дати пріоритет одному протоколу маршрутизації над іншим, ніж, не зрозуміло як, зіставляти пріоритети метрик різних протоколів маршрутизації.
Правило номер 3.
Воно третій тільки тому, що перші 2 місця вже зайняті J
Для того, щоб зрозуміти як організовується anycast в IP мережах, розуміння описаних вище принципів роботи маршрутизації досить.
Для опису роботи anycast розглянемо мережу, в якій працює протокол динамічної маршрутизацією з максимально спрощеною логікою вибору маршруту з різних місць до хоста 192.168.0.2.
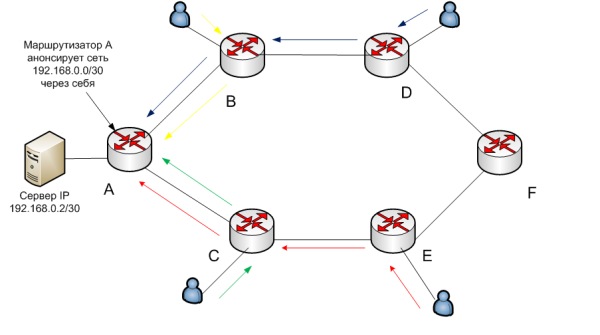
Пріпустімо, працює тієї ж OSPF, при цьом лінки между маршрутизаторами ма ють однаково пропускну здатність и параметр bandwith ніде НЕ налаштованості. Критерієм вибору маршруту в даному випадку, є тільки кількість маршрутизаторів, через які повинні пройти пакети. Стрілками різного кольору вказано шляхи пакетів для того, щоб досягти сервера.
А тепер, для цієї ж мережі включимо ще один фізичний сервер з таким же IP в маршрутизатор F. Цей маршрутизатор, в свою чергу змусимо анонсувати той же префікс через себе.

Очевидно, що в цьому випадку, частина трафіку піде на один сервер, частина на інший.
Таким чином, 2 або більше, різних, але рівноцінних сервера з однаковим IP можна включити в різні географічно віддалені місця. Така схема не тільки не суперечить принципам маршрутизації, але я б сказав навіть, що вона органічно в них вписується.
Що стосується кінцевих користувачів, то для них така схема прозора, більш того, вони від цього виграють, тому що чим менша кількість маршрутизаторів проходить пакет, тим краще з точки зору затримок. Що стосується anycast серверів то для них це теж прозоро. Вони працюють так само як з unicast-ами.
Що до маршрутизаторів, які анонсують через себе префікси, то їм теж абсолютно все одно, анонсує чи ще хтось через себе такий же префікс чи ні. Чи не анонсують префікс маршрутизатори просто вибирають кращий, з їх точки зору, шлях до IP адреси.
У такій схемі є лише одна засідка. Припустимо, користувач, який працює через маршрутизатор B качає по ftp великий файл з сервера, що працює через маршрутизатор А. В цей час зв'язок між А і B переривається. Якби не було anycast-а, таблиці маршрутизації перебудувалися б таким чином, що пакети пішли б в обхід, але все одно, досягли б сервера працює через A, і закачування б не перервалася. У випадку з anycast-му користувач переключиться на сервер, що працює через маршрутизатор F. Оскільки ftp на транспортному рівні використовує tcp, який орієнтований на сесію, то закачування для користувача перерветься. Я не буду детально пояснювати, чому це так, тому що це виходить за рамки статті. В цілому ж, щодо можливості нормального використання орієнтованих на сесію протоколів зі схемами anycast-а, з глобальної точки зору на функціонування Інтернет, думки фахівців розділилися. Одні вважають, що це не доцільно, тому що загрожує частими "обривами" (причому, мало хто здатний буде нормально пояснити, чому раніше не було жодного обриву, а зараз вони є J), інші ж кажуть, що помітних "обривів» не буде, і доводять це на практиці.
Якщо ви будете читати інформацію по anycast-ам, то вам часто буде зустрічатися фраза, що оголошуються IP адреси з певним однаковим префіксом. Підкреслюють це тому, що якщо ви оголосите маршрути до одного і того ж IP з різними префіксами, то працювати anycast не буде, це логічно, якщо ви розумієте логіку маршрутизації, яка була описана вище, а саме, перше правило.
Дійсно, припустимо, ви хочете побудувати систему з трьома anycast серверами, що живуть на однакових IP адреси, при цьому оголосили в маршрутизації 2 з них з префіксом довжиною 28, а третій з префіксом довжиною 29. Тоді схема не буде працювати, так як всі пакети будуть маршрутизироваться на третій маршрут. Якщо ж ви прописали третій маршрут з префіксом довжиною 27, то пакети будуть йти тільки на перші два сервера, третій випаде зі схеми.
Наявність же різних протоколів маршрутизації в мережі і різних метрик всередині протоколів ніяк не впливає на загальну працездатність anycast-ів, цими параметрами можна впливати тільки на навантаження конкретного сервера, як би підключаючи до і відключаючи від цього сервера користувачів, що мають доступ в мережу з через різні маршрутизатори.
Тепер повернемося до наших баранів, тобто кореневих DNS серверів.
Принцип роботи з anycast в глобальному масштабі такий же, як і в локальних мережах. У глобальній мережі Інтернет в якості протоколу динамічної маршрутизації використовується протокол BGP.
В цілому описувати, як все влаштовано, і які проблеми можуть виникнути при включенні anycast-а дуже складно. Сам по собі протокол BGP непросте, а при включенні anycast виникають додаткові не зовсім приємні моменти. існує RFC http://tools.ietf.org/html/rfc4786 , Які описують кращі практики при організації anycast в глобальних масштабах.
Щоб визначити до якого з кореневих anycast серверів йдуть запити, адресовані на той чи інший anycast адреса кореневого DNS сервера, можна використовувати команду.
dig + norec @ X .ROOT-SERVERS.NET HOSTNAME.BIND CHAOS TXT
Де X - буква від A до M для кожного з 13-ти anycast IP адрес серверів.
Якщо у вас є можливість давати такі команди з різних географічно віддалених серверів в мережі, то, можна легко переконатися, що на запити з різних автономних систем приходять відповіді з фізично різних серверів.
Хотілося б висвітлити різні топології, що використовуються різними організаціями, відповідальними за кореневі сервери. Перш, ніж описувати які топології використовується необхідно ввести 2 поняття anycast DNS серверів. Існують, так звані, локальні root anycast сервера і глобальні root anycast сервера. Глобальні сервера - це сервера які доступні в глобальних межах, тобто теоретично всім в Інтернет, хоча, завдяки регуляцій метриками BGP кожен з них доступний тільки з певних місць. Локальні сервера доступні тільки клієнтам декількох найближчих до них провайдерів. Регулюванням того, який це сервер глобальний чи локальний займається протокол BGP. Згідно з тим, які сервера (локальні або глобальні) і в якій пропорції використовуються при організації anycast, розрізняють 3 схеми.
Однакова (flat) - складається тільки з глобальних серверів, використовується для J-root серверів.
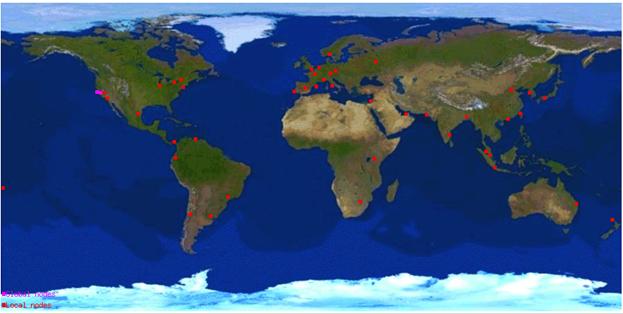
Ієрархічна (hierarchical) складається з декількох географічно близько розташованих глобальних серверів і безлічі локальних серверів використовується для F-root серверів.
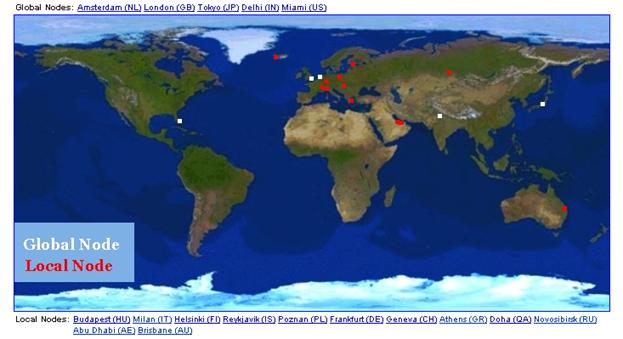
Гібридна (hybrid) складається з географічно розподілених глобальних серверів і також розподілених локальних серверів використовується для K-root серверів.
Ось, наприклад, як виглядає картина глобального розташування для k-root серверів c IP адресою 193.0.14.129, яку адмініструє RIPE www.ripe.net (Гібридна схема).
І для f-root з IP адресою 192.5.5.241, яку адмініструє Internet Systems Consortium, Inc. www.isc.org (Ієрархічна схема).
Як бачите, серед різних організацій відповідальних за кореневі сервери різні підходи. Кожна зі схем ефективна, яка з них більш ефективна питання до кінця не визначений.
Згідно з усіма звітами, результати тестування підтверджують ефективність роботи anycast для root DNS серверів в глобальному режимі, проблеми при роботі DNS з використанням tcp не істотні.
Згідно з дослідженнями, що проводяться з метою виявлення ефективності розподілу трафіку кореневих серверів в глобальних межах, з'ясовано наступне: навантаження на сервера розподіляється ефективно, з точки зору географічного положення користувачів (а значить з точки зору часових затримок відповідей від серверів).
На поточний момент всього в світі 150 root DNS серверів, що більш ніж на порядок більше, ніж початкове число - 13. Більш детальну інформацію про поточний стан справ по кореневих серверів можна дізнатися тут http://www.root-servers.org/
Той факт, що сервера географічно розподілені, робить DoS атаку на них більш складною. Бот мережу, яка зможе вивести з ладу всі кореневі сервери також повинна бути глобально розподіленої. Адже, якщо припустимо, хости атакуючої бот мережі будуть сконцентровані в основному в Європі, жителі Південної Америки навіть не будуть підозрювати про те, що на кореневі DNS проводиться атака.
В Інтернеті можна знайти великий обсяг інформації про технології anycast і зокрема про використання її для DNS. Що стосується рамок даної статті то, на цьому я обмежуся.
Однозначно ніхто не може сказати, чи здатна дана схема з існуючим числом кореневих DNS серверів протистояти розподіленим DoS атак в разі використання бот мереж з мільйонами хостів. Зрозумілим є одне, схема добре масштабується, і навіть якщо, не дивлячись ні на що, поганим хлопцям вдасться завалити глобальну систему DNS, то хороші хлопці у відповідь зможуть її багаторазово посилити. Схоже, хороші хлопці перемагають.
Григорій Сандул, [email protected]
Піде з верхнього або нижнього інтерфейсу?Чому?
Що таке префікс?
Як описується default gateway в префіксах?